CCSP Domain 5 - Cloud Infrastructure Implementation MindMap
Download FREE Audio Files of all the MindMaps
and a FREE Printable PDF of all the MindMaps
Your information will remain 100% private. Unsubscribe with 1 click.
Transcript
Introduction
This is our first MindMap for Domain 5, and we're going to be discussing Cloud Operations. Throughout this MindMap, we will be explaining how these ideas interrelate to help guide your studies. This MindMap is just a small fraction of our complete CCSP MasterClass.

This is the first of three videos for Domain 5. I have included links to the other MindMap videos in the description below. These MindMaps are just a small part of our complete CCSP MasterClass.
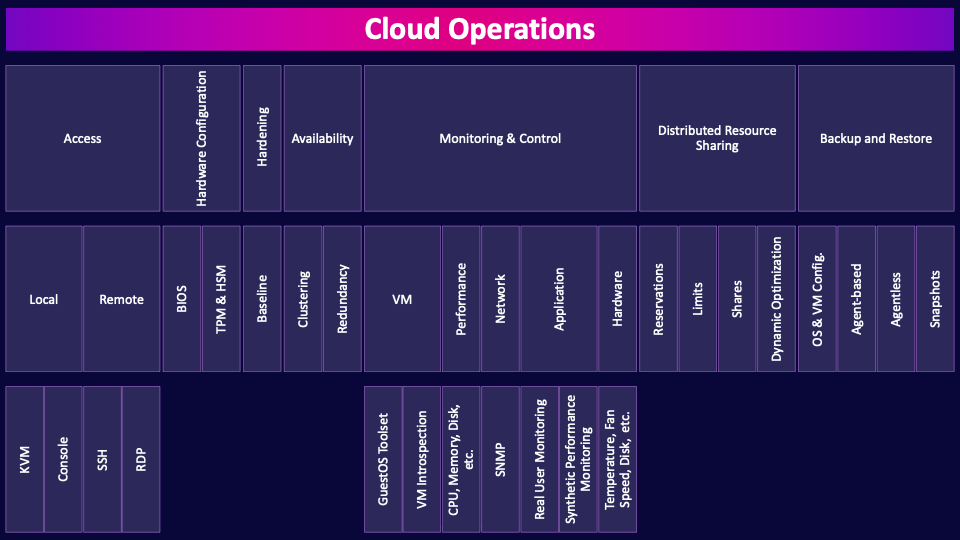
Cloud Operations
Cloud operations (CloudOps) refers to the management, maintenance, and optimization of cloud-based infrastructure, applications, and services. It involves activities like monitoring, performance management, security enforcement, compliance, and resource optimization to ensure smooth, efficient, and reliable cloud environments. CloudOps enables organizations to scale and manage resources effectively, maintain availability, and improve overall system resilience, helping them maximize the benefits of their cloud investments. It’s all important stuff obviously, so let’s get into it.
Access
First up, let’s talk about how you can access systems in the cloud.
Local
Local access methods, like KVM (keyboard, video, mouse) and console access, provide direct, physical-level interaction with cloud devices, often used for initial setup or troubleshooting issues when network-based access is unavailable. These methods grant full control over the system, even during boot processes or when network services are down, making them essential for deeper-level management.
KVM
KVM provides direct, hardware-level access to a device through the keyboard, video monitor and mouse, allowing you to control the keyboard, view video output, and use the mouse as if you were physically present at the machine. This is particularly useful for full control, including during boot processes, BIOS/UEFI configuration, or when the operating system is unresponsive.
Console
Console access usually operates at the command-line level and connects directly to the system's console interface–like the COM port. Console access is typically text-based and it can provide access even if the network configuration is not yet set up or if the operating system has limited functionality. Console access is commonly used for quick troubleshooting, system boot diagnostics, and early setup tasks.
Remote
Remote access methods, such as SSH (Secure Shell) for Linux and RDP (Remote Desktop Protocol) for Windows, enable users to securely connect to cloud devices over the network. Remote methods are efficient for ongoing operations, while local access is typically reserved for situations requiring direct, unrestricted device interaction.
SSH
SSH is a secure, command-line-based protocol mainly used to access Linux or Unix-based systems remotely. It enables encrypted communication over the network, allowing you to execute commands, transfer files, and manage configurations on the target machine.
RDP
RDP is a graphical remote access protocol primarily for Windows systems, allowing you to connect to a device’s full desktop interface remotely. It provides a visual environment where you can interact with applications, files, and system settings through the GUI as if you were sitting at the physical machine.
Hardware Configuration
Hardware configuration in the cloud involves managing settings related to physical-level components. Let’s go through a couple major examples of hardware that needs to be properly configured.
BIOS
The BIOS, the Basic Input/Output System, is firmware stored on a small memory chip on the motherboard. It initializes hardware when the system is turned on. In the cloud, the BIOS can be used to control things like boot order, enable virtualization extensions, enable secure boot, or configure power management.
TPM & HSM
A TPM, a Trusted Platform Module, is a chip built into an endpoint like a laptop or server. TPMs are used to securely store encryption keys, ensure secure boot, and protect sensitive information on an endpoint device.
An HSM, a hardware security module, is a physical device specifically built to securely store and manage encryption keys at the organizational level, not just for a single device. HSMs are dedicated hardware devices for managing cryptographic keys, providing a high level of security for encryption operations.
Hardening
Hardening is the process of securing a system by reducing its attack surface area and minimizing vulnerabilities. Hardening is a critical process that must be done to any new device, system, application, operating system, etc. When we buy something new, it is intentionally not delivered in a locked down and secure state–we need to be able to log into it for the first time and configure it to the specific needs of the environment. Hardening is the critical process of locking anything down and ensuring it remains appropriately locked down in production.
Baseline
Locked down according to what? Typically a baseline. Security baselines are mandatory configuration settings that aim to ensure that a system has a secure foundation of controls. Baselines are essentially just a checklist of things you need to go through to lock something down–to harden it. Disable unnecessary services, disable or remove guest accounts, install all the necessary patches, etc. A baseline should be created for each system and tailored to each system’s specific usage within the environment.
Availability
Availability is about having our information accessible to authorized parties when they need it. That’s pretty important! So let’s talk about just a couple of techniques that can aid in availability.
Clustering
One option for architecting highly available systems is to use clustering. This essentially involves having multiple systems sharing a workload. For example, a cluster of ten webservers sitting behind a load balancer. If one system goes down, there are still nine other members of the cluster running to provide availability.
Redundancy
Redundancy involves having a single primary system and one or more secondary systems to switch over to in case of failures. Unlike with clustering, the redundant secondary systems aren’t doing any work when the primary system is online.
Monitoring & Control
Another critical requirement of cloud operations is the ability to monitor and control a whole range of systems across the cloud.
VM
Let's start with how we can monitor and control VMs.
GuestOS Toolset
Guest OS virtualization toolsets are software agents installed on the operating system of a VM. They can report on performance and other metrics, and also be used to push configuration changes to a VM. So this is a software tool/agent installed on the VM.
VM Introspection
VM introspection is very different. VM introspection allows for monitoring and analyzing the state of a VM from outside the VM itself, usually by the hypervisor. This approach enables the detection of malware, unauthorized changes, or abnormal behaviors without relying on software inside the VM, making this type of monitoring less vulnerable to tampering by attackers. VM introspection from the hypervisor can inspect memory, file systems, and process activity, making it a powerful tool for security monitoring, forensics, and compliance management.
Performance
There are a range of things that we want to monitor to ensure optimal performance.
CPU, Memory, Disk, etc.
These include things like CPU, memory, disk and network bandwidth, which cloud providers must monitor to ensure that their service is meeting customer needs.
Network
Network monitoring in the cloud is essential to ensure security, performance, and availability of cloud resources. By tracking traffic patterns, latency, bandwidth usage, and potential anomalies, organizations can detect and respond to threats like DDoS attacks, unauthorized access, and data breaches. Monitoring helps optimize resource usage, prevent outages, and maintain compliance with security policies and regulations.
SNMP
A useful protocol for network monitoring in SNMP–the Simple Network Management Protocol. SNMP can be used to monitor, manage, and configure network devices such as routers, switches, servers, and workstations. SNMP allows administrators to collect real-time data on network performance, detect issues, and receive alerts for specific events. SNMP can provide insights into device status, resource utilization, error rates, and traffic flow, enabling effective troubleshooting and proactive network maintenance.
Application
Let’s now move on to a couple of common techniques for application performance monitoring.
Real User Monitoring
Real user monitoring–RUM– involves monitoring real users as they use your system. You can monitor their page load times and common errors that pop up, and then address any major problems that real users are encountering.
Synthetic Performance Monitoring
Synthetic performance monitoring involves building agents that simulate user actions. Instead of monitoring real users, you use the agents to test the functionality, availability, and response times of the app.
Hardware
The last aspect of monitoring we’ll talk about is hardware.
Temperature, Fan Speed, Disk, etc.
Cloud providers closely monitor a variety of hardware components to ensure reliability, prevent failures, handle any hardware failures that do occur, and maintain high performance across their services. Various temperatures on devices are carefully tracked to prevent overheating, with fan speeds dynamically adjusted in response to temperature changes for efficient cooling. Power supply units (PSUs) are monitored to detect issues and ensure energy efficiency. Disk health is essential, with metrics like usage, read/write speeds, error rates, and drive temperature constantly analyzed to predict and avoid storage failures. CPU and memory usage are tracked to balance workloads and prevent resource shortages, ensuring steady performance. Network interface cards (NICs) are monitored for health, speed, and error rates to maintain reliable connectivity, while battery backup systems or uninterruptible power supplies (UPS) are checked for health and charge levels to support continuity during power disruptions.
Distributed Resource Sharing
Moving on to the next major topic–DRS. Distributed resource scheduling is an approach for balancing the available resources against the demand from customers. If a cloud provider experiences demand spikes that are difficult for it to handle, it needs orderly mechanisms for sharing its resources amongst customers.
Reservations
Reservations are where customers have agreements for a minimum amount of resources that they will be allocated. As an example, they might have an agreement with their provider that they are guaranteed eight gigabytes of RAM for a specific VM. Reservations can be set for compute, network and storage. A reservation is essentially a guaranteed minimum.
Limits
A limit is the maximum amount of resources that a customer will be allocated for the billing period. Limits can be useful if you don’t want to run into an enormous cloud bill from some unexpected error, breach or unexpected usage. If you set a limit and you exceed it, your provider will stop providing you with resources. Limits are essentially defined maximums.
Shares
Shares define the relative priority of resource access when multiple VMs or applications compete for the same resources. Higher shares increase priority, allowing an application to access more resources in contention situations. Shares only matter if there is a resource contention issue–they essentially establish who gets priority in the event of a resource contention issue.
Dynamic Optimization
Dynamic optimization automatically adjusts resource allocation based on real-time demand and usage patterns. This helps maximize efficiency by reallocating underutilized resources and responding to workload changes without manual intervention. It also helps to ensure that customer reservations are met. For example, if a compute node is running low on resources, it can live-migrate a workload (a VM or a container) away to another compute node that has more available resources. Dynamic optimization is an important technique for the rapid elasticity and scalability of cloud services.
Backup and Restore
Backups and restoration are another essential operation in the cloud for protecting against data loss, corruption, or accidental deletion. With cloud environments often hosting critical applications and data, having reliable backups ensures that customers can recover important information in case of hardware failure, cyberattacks, or human error. Restoration processes allow for quick data retrieval and service continuity, minimizing downtime and potential revenue loss. Regular backups also support compliance with data protection policies and regulations. Put simply, backups and restoration are crucial for maintaining data integrity, availability, and reliability in the cloud. There is a lot of stuff that we have to think about when backing up in the cloud, but we’re just going to focus on VMs here.
OS & VM Config.
It’s obviously important to backup the data stored in our VMs, but we also need to backup our OS and VM configurations. If we need to recover a VM, we need to have a backup of the VM’s virtual hardware configuration and the configuration of the OS. So it’s important to ensure all of this data is backed up.
Agent-based
Lets talk about a couple of methods that can be used for backing up VMs.
Agent-based backups involve installing an agent on every VM. The agent installed on a VM can ensure the data is backed-up as required.
Agentless
Another approach is agentless. As the name suggests, agentless backups don’t involve any agents (software installed on the VM). Instead, there is a utility that remotely logs into a system, backups up the files, and then logs out again.
Snapshots
The final backup method we’ll talk about–and the final item in this MindMap–is snapshots. Snapshots capture the exact state and data of a VM at a specific point in time, including its disk, memory, and settings. Essentially every bit of data related to a VM. Snapshots provide a quick and reliable way to back up VMs, enabling easy rollback to a previous state if needed, such as after a failed update, system crash, or data corruption. Snapshots are especially useful for testing, development, forensics and recovery purposes.
That's it for our overview of cloud operations within Domain 5, covering the most important concepts you need to know for the exam.

If you found this video helpful you can hit the thumbs up button and if you want to be notified when we release additional videos in this MindMap series, then please subscribe and hit the bell icon to get notifications.
I will provide links to the other MindMap videos in the description below.
Thanks very much for watching! And all the best in your studies!